The goal of this section is to provide an example how Jumpshot's ViewMap can be used to study the performance of threaded MPI applications. Let's say we are interested to find out the performance of different MPI implementations in a threaded environment. We will use a simple mult-threaded MPI program to see if there is any preformance difference. The test program, pthread_sendrecv.c, used here first creates multiple threads in each process. Each spawned thread then duplicates the MPI_COMM_WORLD to form a ring, i.e. each thread sends a message to its next rank and receives a message from its previous rank within same duplicated MPI_COMM_WORLD to form a ring. The program is shown at the end of the document. MPE is built with -enable-threadlogging4.4 and -disable-safePMPI4.5. The most accessible MPI implementations with MPI_THREAD_MULTIPLE support are MPICH2 and OpenMPI. We will use the latest stable release of MPICH2, 1.0.5p4, and OpenMPI, 1.2.3 for this demonstration. Since OpenMPI has the option to enable progress thread in additional to the standard thread support, we will build 2 different versions of OpenMPIs for this little experiment. The experiment will be performed on 4 AMD64 nodes running Linux Ubuntu 7.04, each node consists of 4 cores and the test program will be running with 1 to 6 extra threads to see if the oversubscribing has any effect on the send and receive performance.
Table 4.2 shows the total duration of the 4-process run with various numbers of child threads. The data shows that as the number of child threads increases, so is the total runtime. For MPICH2, the runtime increase is modest for each additional thread. For OpenMPI+progress_thread, the performance isn't as good as MPICH2 but it is still reasonable as the number of threads increases. However for OpenMPI without progress thread support, the runtime increases drastically as there are 3 child threads or more. The situation becomes very bad as the node becomes oversubscribed, i.e. when there are 5 or more child threads. Now we are going to use MPE logging and Jumpshot to find out what happens.
|
|
The problematic data in the last column of Table 4.2 are being analyzed with two Jumpshot viewmaps for each run. They are shown in Figures 4.7, 4.8,4.9,4.10 and 4.11. The legend for these pictures are shown in Figure4.6.
The extra viewmaps provided in MPE logging are:
1) Process-Thread view: where each thread timeline is shown nested under the process timeline it belongs to. Since we are only running 4 processes, only 4 process timelines here.
2) Communicator-Thread view: where each thread is shown nested within the communicator timeline. Since we are runing with 2 to 6 child threads where a duplicated MPI_COMM_WORLD is created for each thread, so we expect to see 3 to 7 major communicator timelines. MPI_COMM_WORLD is always labeled as 0 in CLOG2 converted SLOG-2 file and other duplicated MPI_Comm is labeled with other integer depends on the order of when it is being created.
When the timeline window of the process-thread view first shows up,
only process timelines are visible, i.e. all the thread timelines
are nested within the process timeline. User needs to use the Y-axis
LabelExpand button  or
Alt-E to expand each process timeline to reveal the thread
timeline. Similarly, user can use the Y-axis LabelCollapse button
or
Alt-E to expand each process timeline to reveal the thread
timeline. Similarly, user can use the Y-axis LabelCollapse button
 or Alt-C to collapse
the thread timeline back to their corresponding process timeline.
Similarly for the communicator-thread view, the Y-axis LabelExpand
and LabelCollapse buttons should be used to expand and collapse the
communicator timelines.
or Alt-C to collapse
the thread timeline back to their corresponding process timeline.
Similarly for the communicator-thread view, the Y-axis LabelExpand
and LabelCollapse buttons should be used to expand and collapse the
communicator timelines.
Figures 4.8, 4.9, 4.10 and 4.11 clearly demonstrate that there is some kind of communication progress problem in OpenMPI when used without progress thread. Without alternating between communicator-thread and process-thread views, it would be difficult to identify the existence of a progress engine problem.
|
[process-thread view]

[communicator-thread view] 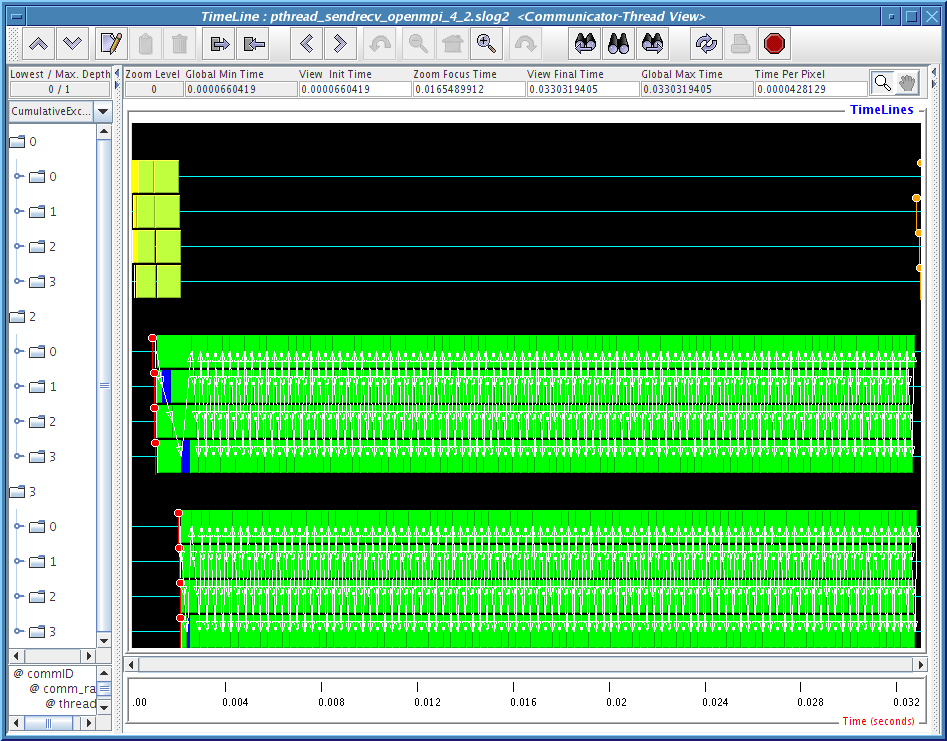
|
|
[process-thread view]
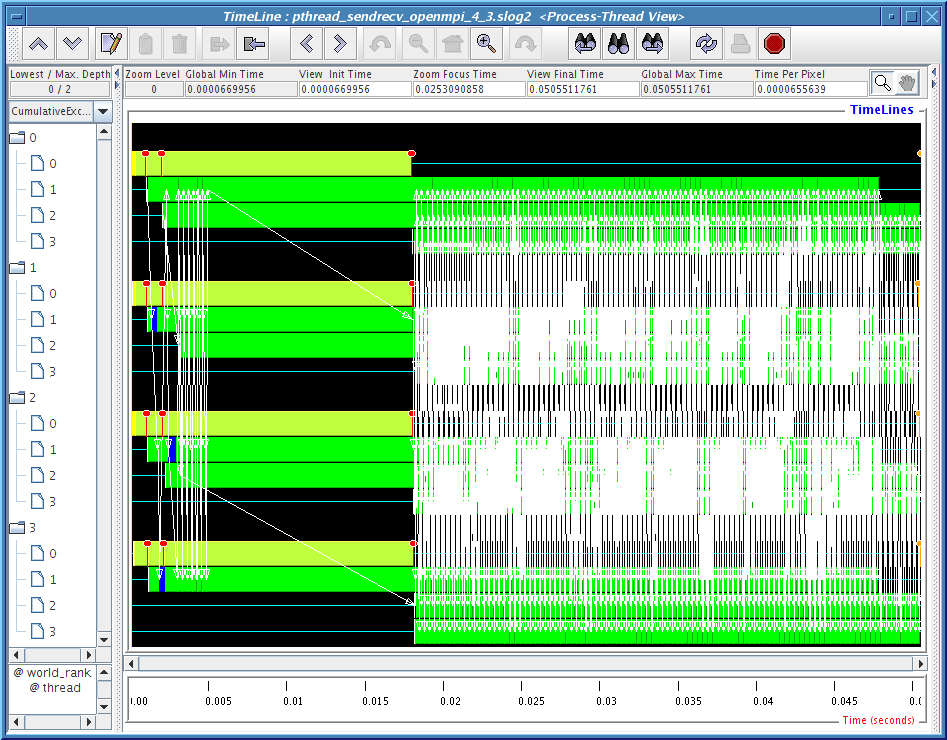
[communicator-thread view] 
|
|
[process-thread view]
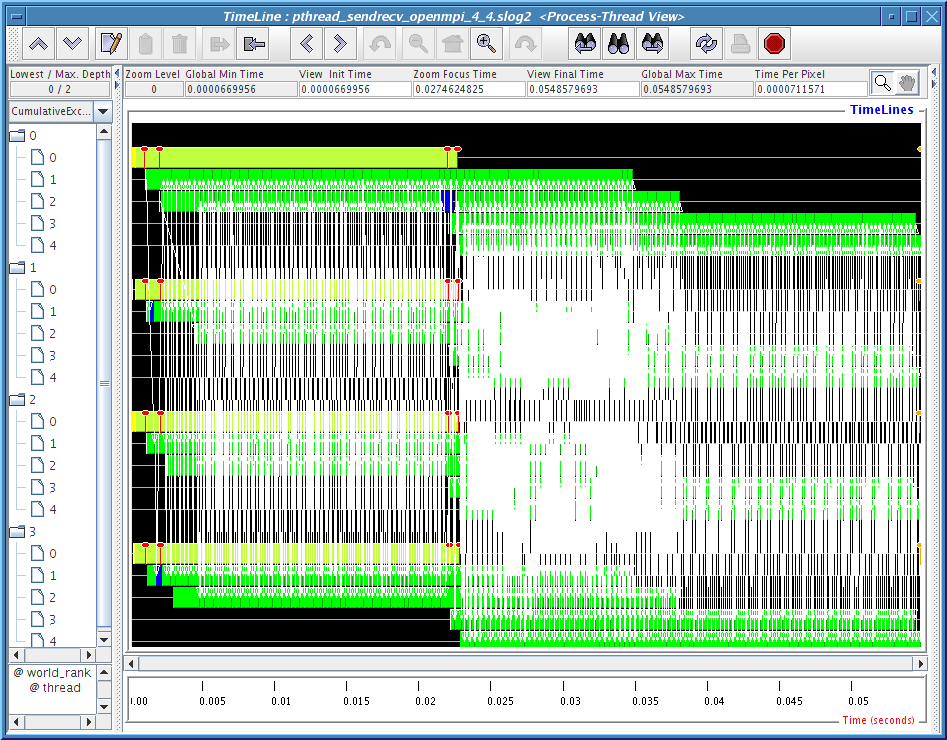
[communicator-thread view] 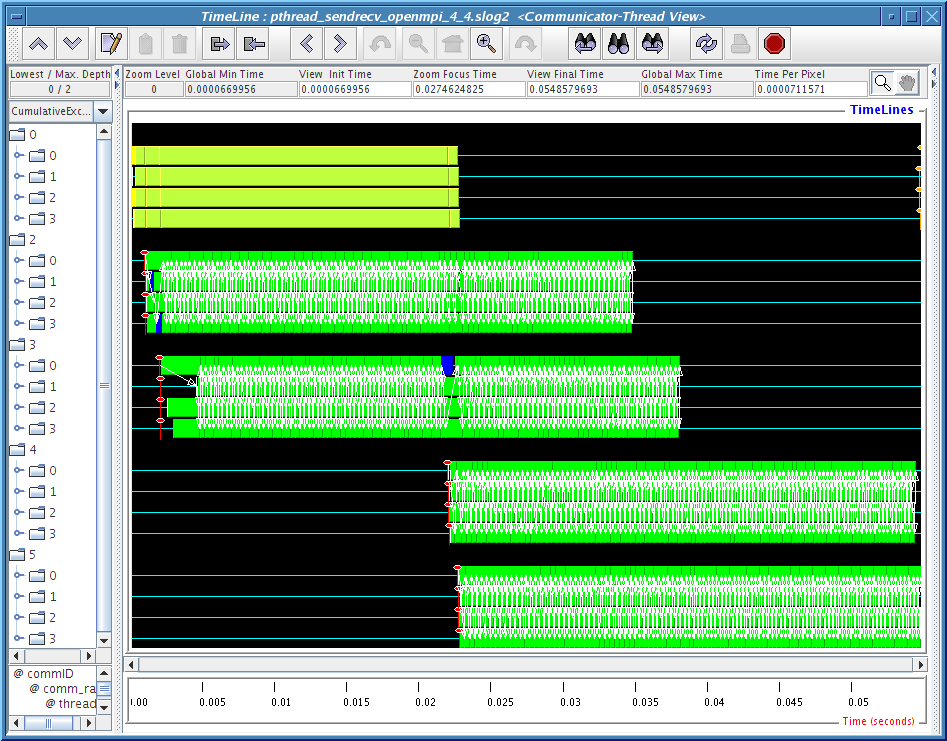
|
|
[process-thread view]
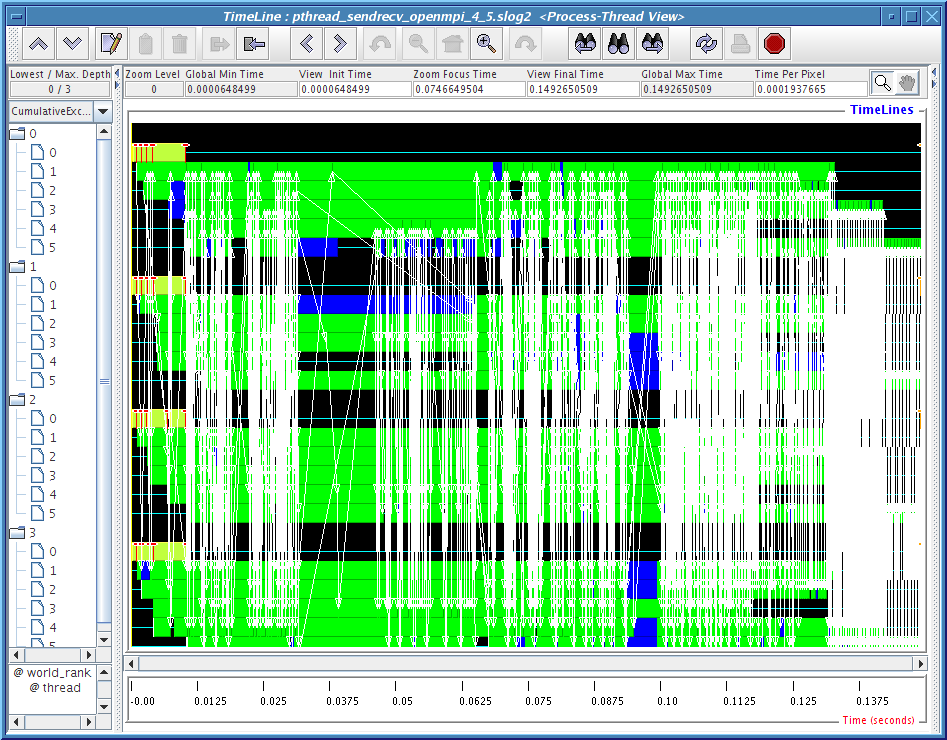
[communicator-thread view] 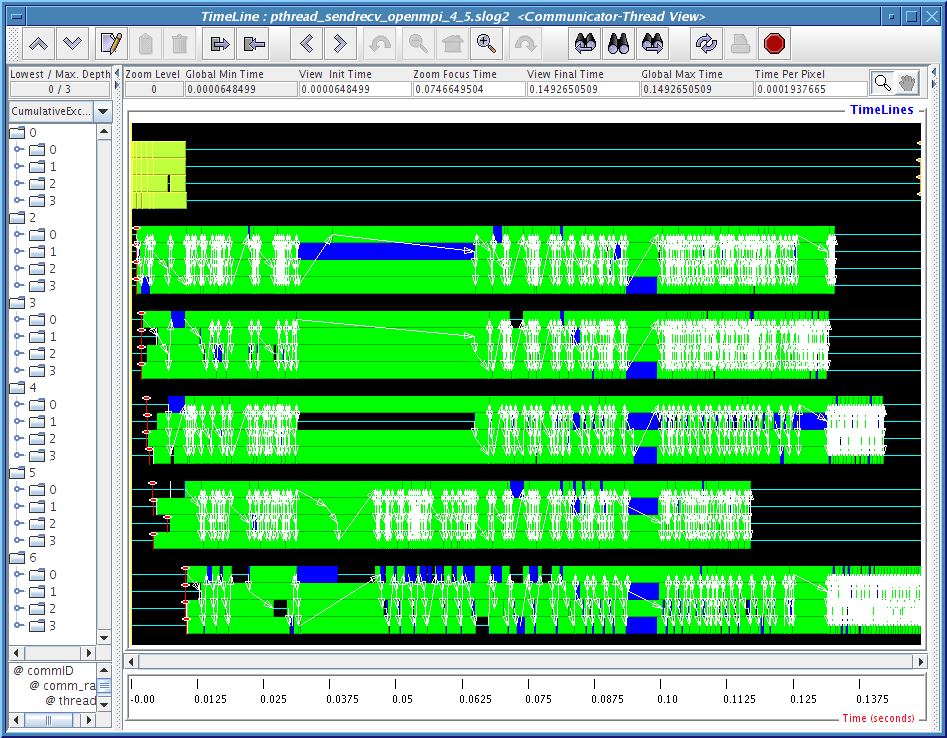
|
|
[process-thread view]

[communicator-thread view] 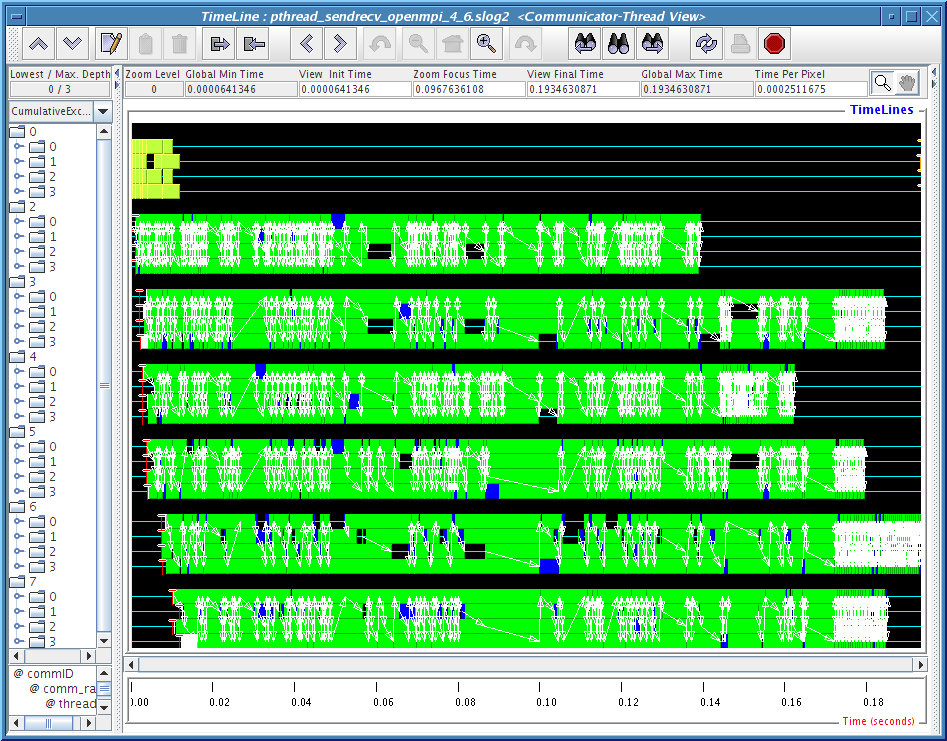
|