|
AdjoinableMPI
|
|
AdjoinableMPI
|
Directories and libraries are organized as follows:
PlainC : pass through to MPI implementations of the user interface; no reference to ADTOOL interfaces; to be renamedTape : sequential access storage mechanism default implementation (implemented as doubly linked list) to enable forward/reverse reading; may not reference ADTOOL or AMPI symbols/types; may reference MPIBookkeeping : random access storage for AMPI_Requests (but possibly also other objects that could be opaque)Common : the AD enabled workhorse; here we have all the common functionality for MPI differentiation;Symbol prefixes:
AMPI_ to be used for anything in MPI replacing the MPI_ prefix; not to be used for symbols outside of the user interfaceTAPE_AMPI_ to be used for the Tape sequential access storage mechanism declared in ampi/tape/support.hBK_AMPI_: Bookkeeping random access storage mechanism declared in ampi/bookkeeping/support.hADTOOL_AMPI_ to beA central concern is the handling of non-blocking sends and receives in combination with their respective completion, e.g. wait, waitall, test. Taking as an example
The adjoint action for MPI_Wait will have to be the MPI_Isend of the adjoint data associated with the data in buffer b. The original MPI_Wait does not have any of the parameters required for the send and in particular it does not have the buffer. The latter, however, is crucial in particular in a source transformation context because, absent a correct syntactic representation for the buffer at the MPI_Wait call site one has to map the address &b valid during the forward sweep to the address of the associated adjoint buffer during the reverse sweep. In some circumstances, e.g. when the buffer refers to stack variable and the reversal mode follows a strict joint scheme where one does not leave the stack frame of a given subroutine until the reverse sweep has completed, it is possible to predetermine the address of the respective adjoint buffer even in the source transformation context. In the general case, e.g. allowing for split mode reversal or dynamic memory deallocation before the adjoint sweep commences such predetermination requires a more elaborate mapping algorithm. This mapping is subject of ongoing research and currently not supported.
On the other hand, for operator overloading based tools, the mapping to a reverse sweep address space is an integral part of the tool because there the reverse sweep is executed as interpretation of a trace of the execution that is entirely separate from the original program address space. Therefore all addresses have to be mapped to the new adjoint address space to begin with and no association to some adjoint program variable is needed. Instead, the buffer address can be conveyed via the request parameter (and AMPI-userIF bookkeeping) to the MPI_Wait call site, traced there and is then recoverable during the reverse sweep. Nevertheless, to allow a common interface this version of the AMPI library has the buffer as an additional argument to in the source-transformation-specific AMPI_Wait_ST variant of AMPI_Wait. In later editions, when source transformation tools can fully support the address mapping, the of the AMPI library the AMPI_Wait_ST variant may be dropped.
Similarly to conveying the buffer address via userIF bookkeeping associated with the request being passed, all other information such as source or destination, tag, data type, or the distinction if a request originated with a send or receive will be part of the augmented information attached to the request and be subject to the trace and recovery as the buffer address itself. In the source transformation context, for cases in which parameter values such as source, destination, or tag are constants or loop indices the question could be asked if these values couldn't be easily recovered in the generated adjoint code without having to store them. Such recovery following a TBR-like approach would, however, require exposing the augmented request instance as a structured data type to the TBR analysis in the languages other than Fortran77. This necessitates the introduction of the AMPI_Request, which in Fotran77 still maps to just an integer address. The switching between these variants is done via configure flags, see Library - Configure, Build, and Install.
As mentioned in Nonblocking Communication and Fortran Compatibility the target language may prevent the augmented request from being used directly. In such cases the augmented information has to be kept internal to the library, that is we do some bookkeeping to convey the necessary information between the nonblocking sends or receives and the and respective completion calls. Currently the bookkeeping has a very simple implementation as a doubly-linked list implying linear search costs which is acceptable only as long as the number of icomplete nonblocking operations per process remains moderate.
Whenever internal handles are used to keep trace (or correspondence) of a given internal object between two distant locations in the source code (e.g. file identifier to keep trace of an opened/read/closed file, or address to keep trace of a malloc/used/freed dynamic memory, or request ID to keep trace of a Isend/Wait...) we may have to arrange the same correspondence during the backward sweep. Keeping the internal identifier in the AD stack is not sufficient because there is no guarantee that the mechanism in the backward sweep will use the same values for the internal handle. The bookkeeping we use to solve this problem goes as follows:
Simple workaround for the "request" case: This method doesn't rely on TBR.
A central question for the implementation of tangent-linear mode becomes whether to bundle the original buffer b with the derivative b_d as pair and communicate the pair or to send separate messages for the derivatives.
b and b_d are already given as separate entities as is the case in association by name, see Introduction.An earlier argument against message shadowing was the difficulty of correctly associating message pairs while using wildcards. This association can, however, be ensured when a the shadowing message for the b_d is received on a communicator comm_d that duplicates the original communicator comm and uses the actual src and tag values obtained from the receive of the shadowed message as in the following example:
This same approach can be applied to (user-defined) reduction operations, see Reduction operations, in that the binomial tree traversal for the reduction is shadowed in the same way and a user defined operation with derivatives can be invoked by passing the derivatives as separate arguments.
The above approach is to be taken by any tool in which b and b_d are not already paired in consecutive memory such as association by name as in Tapenade or by implementation choice such as forward interpreters in Adol-C where the 0-th order Taylor coefficients live in a separate array from the first- and higher-order Taylor coefficients. Tools with association by address (OpenAD, Rapsodia) would have the data already given in paired form and therefore not need messsage shadowing but communicate the paired data.
About MPI_Types and the "active" boolean: One cannot get away with just an "active" boolean to indicate the structure of the MPI_Type of the bundle. Since the MPI_Type definition of the bundle type has to be done anyway in the differentiated application code, and is passed to the communication call, the AMPI communication implementation will check this bundle MPI_Type to discover activity and trace/not trace accordingly.
For the operator overloading, the tool needs to supply the active MPI types for the built-in MPI_datatypes and using the active types, one can achieve type conformance between the buffer and the type parameter passed.
Idea - use an AMPI_Win instance (similar to the AMPI_Request ) to attach more information about the things that are applied to the window and completed on the fence; we execute/trace/collect-for-later-execution operations on the window in the following fashion
forward:
upon hitting a fence in the forward sweep:
for the adjoint of a fence : 0. for each operation on the window coming from the previous fence: 0.1 op isa GET then x_bar=0.0 0.2 op isa PUT/accum= then x_bar+=t21 0.3 op isa accum+ then x_bar+=t22
(Written mostly in the context of ADOL-C.) MPI allows the user to create typemaps for arbitrary structures in terms of a block count and arrays of block lengths, block types, and displacements. For sending an array of active variables, we could get by with a pointer to their value array; in the case of a struct, we may want to send an arbitrary collection of data as well as some active variables which we'll need to "dereference". If a struct contains active data, we must manually pack it into a new array because
When received, the struct is unpacked again.
When the user calls the AMPI_Type_create_struct_NT wrapper with a datamap, the map is stored in a structure of type derivedTypeData; the wrapper also generates an internal typemap that describes the packed data. The packed typemap is used whenver a derived type is sent and received; it's also used in conjunction with the user-provided map to pack and unpack data. This typemap is invisible to the user, so the creation of derived datatypes is accomplished entirely with calls to the AMPI_Type_create_struct and AMPI_Type_commit_NT wrappers.
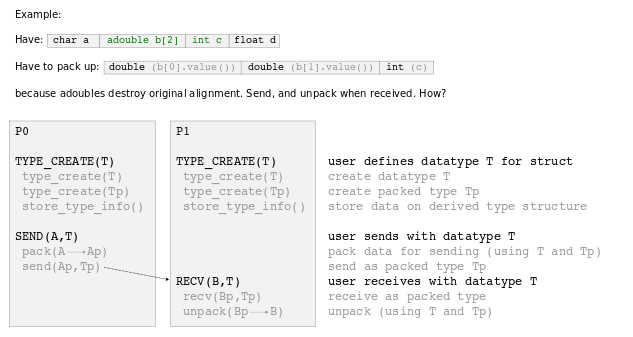
AMPI currently supports sending structs with active elements and structs with embedded structs. Packing is called recursively. Functions implemented are AMPI_Type_create_struct_NT and AMPI_Type_contiguous_NT. A wrapper for _Type_vector can't be implemented now because the point of that function is to send noncontiguous data and, for simplicity and efficiency, we're assuming that the active variables we're sending are contiguous.
Worth noting: if we have multiple active variables in a struct and we want to send an array of these structs, we have to send every active element to ensure that our contiguity checks don't assert false.
Since operator overloading can't enter MPI routines, other AMPI functions extract the double values from active variables, transfer those, and have explicit adjoint code that replaces the automated transformation. This is possible because we know the partial derivative of the result. For reductions, we can also do this with built-in reduction ops (e.g., sum, product). But we can't do this for user-defined ops because we don't know the partial derivative of the result.
(Again explained in the context of ADOL-C.) So we have to make the tracing machinery enter the Reduce and perform taping every time the reduction op is applied. As it turns out, MPICH implements Reduce for derived types as a binary tree of Send/Recv pairs, so we can make our own Reduce by replicating the code with AMPI_Send/Recv functions. (Note that derived types are necessarily reduced with user-defined ops because MPI doesn't know how to accumulate them with its built-in ops.) So AMPI_Reduce is implemented for derived types as the aforementioned binary tree with active temporaries used between steps for applying the reduction op. See AMPI_Op_create_NT.
 1.8.4
1.8.4 
